
Bias(偏差):用所有可能的训练数据集训练出的所有模型的输出平均值和真实模型输出值之间的差异.
MSE(均方误差)
Variance(误差): 不同训练集训练出的模型,输出值之间的差异
@todo
Cross-Validation(交叉校验)
- LOOCV(Leave-one-out cross-validation)
- 定义: 用一个数据作为测试集,其他的数据都作为训练集,并将此步骤重复N次(N为数据集的数据数量)
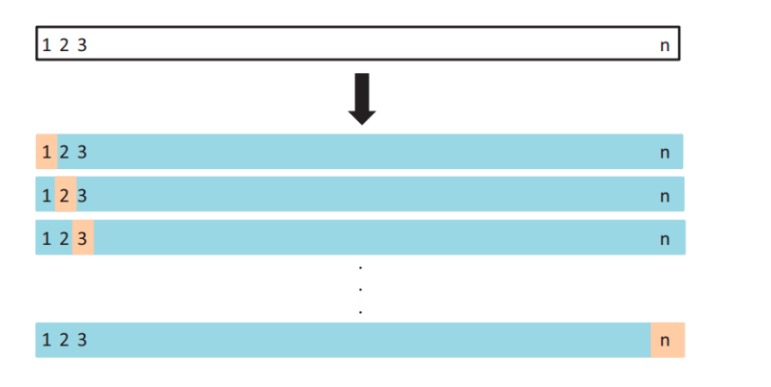 ===>
===> 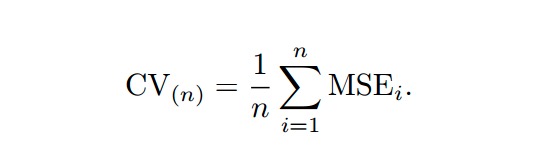 ===>
===> 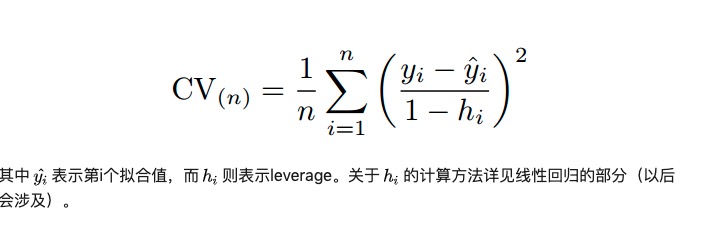
- 定义: 用一个数据作为测试集,其他的数据都作为训练集,并将此步骤重复N次(N为数据集的数据数量)
- KFCV(K-fold cross-validation)
- 定义: 又名k折交叉验证. 用1/k份数据做测试集(包含数据量>=1个), 重复k次(k经验值: 5or10)

- 定义: 又名k折交叉验证. 用1/k份数据做测试集(包含数据量>=1个), 重复k次(k经验值: 5or10)
- Bias-Variance Trade-Off for k-Fold Cross-Validation
- 定义: K的选取是一个Bias和Variance的trade-off。
- Cross-Validation on Classification Problems

BaseRate Fallacy(基本比率谬误)
- 事实结果和大面积群体认知有出入的基本比率(不考虑数据分布前提下产生的错误认知)
- 故事1:
大多数人都会觉得:爱看书的人是图书管理员的可能性大?这就是因为我们忽略了图书管理员和销售员两者在整体人群里的基本分布,或者叫基本比率。这便是基本比率谬误(base rate fallacy)。 - 故事2:
有近7成的淘宝、天猫用户已经找到伴侣,仅3成单身? why? 了解了基本比率谬误,我们就能明白:这个数据显然忽略了单身和非单身的基本比率!
- 故事1:
BaseLine Model:
- 定义: 机器学习领域术语, 通常情况做的结果预测
- 意义: 一个参考值,一个基准值或者称为 了解问题的基线在哪里.
DIY Loss AND Metric Function
- loss_function : 训练模型的优化目标函数
- custom_metric: 训练是输出的评估指标, 作为模型训练的参照, 非实际优化目标
- eval_metric: 监控模型过拟合及作为选择最优模型的参考
CatBoost Tip
- iterations + learning_rate
- 默认迭代1k, 减小iterations,相应增大learning_rate,促进结果收敛
- boosting_type
- 小数量集推荐使用Ordered, 其他使用Plain
- one_hot_max_size
- 设置使用one-hot编码的上限值
- colsample_bylevel(rsm) 0<x<=1
- 好几百维以上特征的情况下,这个参数非常有效,可以有效的加速训练同时保持较好的结果
- max_ctr_complexity
- 特征组合的最大特征数量. 使用k个特征做特征组合处理,优化贪心算法的耗时问题
- depth
- 树深。大多数情况下,在4-10之间,可以在6-10之间多加调试
- l2_leaf_reg
- L2正则系数,多尝试不同的取值
- has_time
- 数据集是时间序列,需要考虑样本的先后关系,则可以设置该参数
- loss_function(objective)
- 损失函数
1 | % CatBoostClassifier? |